

مورداستفاده علم داده در مشاغل مختلف :
علم داده در مشاغل مختلف که شاید در تصور افراد نباشد موجب رفع مشکلات کاری و بالابردن راندمان و بهره وری آن حوزه می گردد.
مورداستفاده علم داده در پزشکی :
- محققین پزشکی از علم داده برای نظارت و پیشگیری از مشکلات سلامتی استفاده میکنند. این کار را از طریق جمعآوری دادهها در مورد الگوهای خواب، سطح گلوکز خون، فعالیت مغز و غیره انجام می دهند و سپس دادهها را تجزیه و تحلیل میکنند تا تغییرات را بررسی کنند و اختلالات یا مشکلات سلامتی احتمالی را تشخیص دهند.
- همچنین، علم داده با تجزیه و تحلیل داده های تصویر برداری به بهبود دقت تشخیص کمک میکند. و دردرمان بیمارهای کشنده ای مثل سرطان و … کمک شایانی می نماید.
مورد استفاده علم داده در امورمالی :
- کسانی که دربازارهای مالی فعالیت دارند با دانش علم داده میتوانند به تجزیه و تحلیل ریسک بپردازند. این کار به آنها کمک میکند تا سطح ریسک مربوز به تصمیم گیریهای مالی را بدانند.
- همچنین، علم داده قادر به جلوگیری و کشف تقلب در بخش مالی می باشد.
- متخصصین مالی میتوانند باکمک علم داده، خدمات مالی شخصیسازی شده را برای مشتریان ایجاد کنند.
کاربرد علم داده در صنایع ساخت و تولید :
- در صنعت تولید، ما ازتجزیه و تحلیل داده ها برای نظارت بر ماشینها و تجهیزات درجهت جلوگیری از خرابی ماشین آلات و کشف دلایل احتمالی خرابی آنها در آینده بهره ببریم .
- همچنین علم داده در مورد بهترین و مقرون به صرفهترین تجهیزاتی که تولیدکنندگان میتوانند خریداری کنند، ارائه می دهد که به بازگشت سرمایه کمک میکند.
- علم داده در پیشبینی تغییرات بازارنیز کمک میکند و به تولیدکنندگان این امکان را میدهد تا با توجه به نیازهای بازار تصمیمات تولیدی مهمی را بگیرند.


-
-
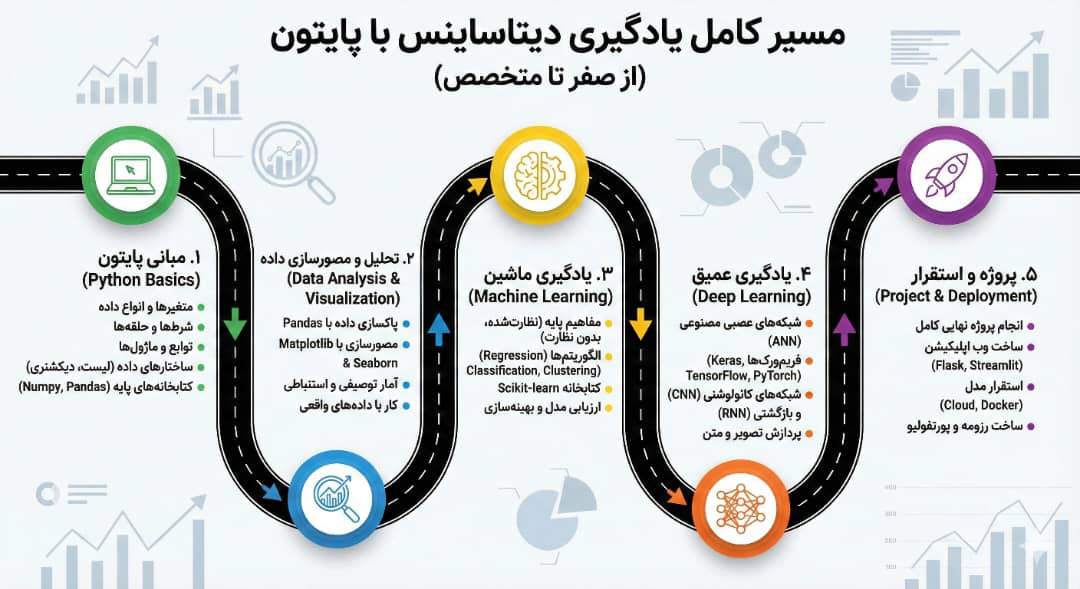
آشنایی با مفهوم علم داده
- √ تعریف علم داده، هوش مصنوعی و یادگیری ماشین و ارتباط آنها با یکدیگر
- √ بررسی کامل چرخه حیات یک پروژه علم داده (از تعریف مسئله تا استقرار مدل)
- √ مطالعه موردی کاربردهای واقعی و موفق علم داده در صنایع مختلف ایران و جهان
- √ بررسی اثرات یادگیری علم داده برای آینده شغلی شما
-
-
-
استفاده از آمار در دیتا ساینس
- √ مروری جامع و کاربردی بر مفاهیم کلیدی آمار توصیفی (شاخصهای مرکزی، شاخصهای پراکندگی، انواع توزیعهای آماری مهم)
- √ مقدمهای بر آمار استنباطی (مفاهیم نمونهگیری، برآورد نقطهای و فاصلهای، آزمون فرض آماری)
- √ اهمیت درک آماری برای تفسیر صحیح نتایج مدلهای یادگیری ماشین
-
آشنایی با نرم افزارهای اکسل و پاوربی آی
آشنایی با محیط اکسل و توانایی های آن
آشنایی با نرم افزار پاوربی آی و توانایی ها ی آن
-
-
آشنایی با محیط گوگل کولب
- √ معرفی کامل محیط گوگل کولب به عنوان یک ابزار آنلاین، رایگان و قدرتمند برای اجرای کدهای پایتون.
- √ نحوه ایجاد و مدیریت نوتبوکها، کار با سلولهای کد و متن، نصب کتابخانههای مورد نیاز.
- √ استفاده بهینه از منابع رایگان گوگل کولب (CPU, GPU, TPU).
- √ آشنایی مختصر با محیط ژوپیتر نوتبوک برای کار به صورت آفلاین.
-
-
-
کاربا کتابخانه های آماری پایتون ….
- √ کار با کتابخانههای آماری پایتون مانند SciPy.stats و Statsmodels.
- √ انجام عملی آزمونهای فرض متداول (مانند t-test, ANOVA, Chi-squared test).
- √ محاسبه ضرایب همبستگی و تحلیل رگرسیون ساده با استفاده از ابزارهای آماری.
- √ تفسیر خروجیهای آماری و نتیجهگیری بر اساس آنها.
-
کارحرفه ای با داده ها
برای جمعآوری، پاکسازی، دستکاری، تحلیل و مصورسازی دادهها به صورت کاملاً عملی و حرفهای مسلط خواهید شد. این مهارتها، پایه و اساس هر پروژه علم داده موفق است و در دوره پایتون آینده برتر نیز به صورت مقدماتی پوشش داده میشود، اما در این دوره به طور تخصصی برای علم داده به کار گرفته خواهند شد.
-
-
کاربا کتابخانه Pandas…
- کار با ساختارهای داده اصلی Pandas: Series و DataFrame.
- خواندن و نوشتن داده از فرمتهای مختلف (CSV, Excel, JSON, SQL databases).
- روشهای پیشرفته انتخاب، فیلتر کردن و نمونهگیری دادهها (Slicing, Dicing, Indexing).
- مرتبسازی، رتبهبندی و گروهبندی دادهها (Aggregation, GroupBy operations).
- ادغام، ترکیب و تغییر شکل دیتافریمها (Merging, Joining, Concatenating, Pivoting).
- کار با دادههای زمانی (Time Series Data).
- تکنیکهای مؤثر برای مدیریت دادههای گمشده (Missing Values Imputation) و دادههای پرت (Outliers).
-
-
-
کاربا کتابخانه Numpy
- √ کار با آرایههای چندبعدی (ndarrays) و انواع دادههای Numpy.
- √ انجام عملیات برداری و ماتریسی به صورت بهینه (Vectorization).
- √ استفاده از توابع ریاضی، آماری و جبر خطی پیشرفته در Numpy.
- √ تولید اعداد تصادفی و کار با توزیعهای مختلف.
-
-
-
مصورسازی داده ها
- √ اصول و مبانی مصورسازی مؤثر دادهها.
- √ خلق انواع نمودارهای استاندارد و پیشرفته (نمودار خطی، میلهای، پراکندگی، هیستوگرام، نمودار جعبهای (Box Plot)، نمودار ویولن (Violin Plot)، نقشه حرارتی (Heatmap)، نمودار جفتی (Pair Plot)
- √ سفارشیسازی کامل ظاهر نمودارها (عناوین، برچسبها، رنگها، فونتها، لجند).
-
نام دوره : Data science(علوم داده)
مدت : 40 ساعت
نوع کلاس : خصوصی – حضوری
پیش نیاز : دوره جامع پایتون – دوره POWER BI
شهریه : ساعتی 480,000 تومان

رابطه پایتون و علم داده :
دانشمندان علم داده برای اینکه از ظرفیت کامپیوترها استفاده کنند، باید با زبانهای برنامهنویسی مثل پایتون آشنایی داشته باشند. زبانهایی که بعضی از آنها به صورت تخصصی برای این دانش طراحی شده و برخی دیگر نیز چندمنظوره هستند.
اگرچه تنوع زبانهای برنامهنویسی مناسب برای دیتا ساینس بسیار بالاست، اما زبان برنامه نویسی پایتون از بالاترین کاربرد و محبوبیت بین این زبان ها برخورداراست .
دلایل انتخاب زبان پایتون به عنوان پیش نیاز برای ورود به حوزه علم داده :
√ یادگیری آسان
زبان پایتون آنقدر ساده طراحی شده که میتوان آن را به یک بچه 12 ساله نیز آموزش داد . در مجتمع فنی آینده برتر دوره های مختلف پایتون برای نوجوانان و بزرگسالان برگزارمی شود که اگر کارآموز از هوش ریاضی متوسط و پشتکار برخوردار باشد به راحتی می تواند این زبان برنامه نویسی محبوب را بیاموزد.
√ تنوع و کاربرد بالای کتابخانههای پایتون
یکی از مهمترین دلایلی که موجب سازگاری علم داده با پایتون می باشد ، کتابخانههای قدرتمند و در حال توسعه این زبان است. کتابخانههای این برنامه در سالهای اخیر رشد چشمگیری داشتهاند و بسیاری از آنها نیز به طور تخصصی برای علم داده، دادهکاوی، یادگیری ماشین و هوش مصنوعی توسعه داده شدهاند.
استفاده از این کتابخانهها کار متخصصان داده را بسیار راحت میکند.
4 نمونه از معروفترین کتابخانههای پایتون عبارتند از:
Numpy : مناسب برای استفاده از الگوریتمهای خطی، توابع پیچیده ریاضی و محاسبات عددی.
Pandas : این کتابخانه طیف وسیعی از توابع را برای ساختاربندی و عملیات بر روی دادهها در اختیار شما قرار میدهد.
SciPy : این کتابخانه برای فعالیتهای رایج علوم داده با پایتون، نظیر درونیابی دادهها، الگوریتمهای خطی و پردازش سیگنالها کاربرد دارد.
Scikit-learn : یکی از محبوبترین و کاربردیترین کتابخانههای یادگیری ماشین مختص زبان برنامهنویسی پایتون است که در طبقهبندی، خوشهبندی و رگرسیون دادهها کاربرد دارد.
√کاربرد پایتون در حوزه یادگیری ماشین (machin learnning)
- پایتون به بهترین و آسانترین شکل در یادگیری ماشین مورد استفاده است .
- این زبان انجام محاسبات ریاضی را که در اجرای الگوریتمها بسیار مفید است را آسان می کند.
- با استفاده از کتابخانه های Tensorflow، Scikit-learn ،PyBrain پایتون ، حوزههای مختلف علوم داده با پایتون قابل توسعه و اجرا می باشد .
√دیداری کردن دادهها با پایتون
بصریسازی یکی از مراحل انتهایی علم داده برای ارائه دیدگاه های استخراج شده از دادهها به مدیران سازمان است. گسترش تکنیکهای بصریسازی داده در پایتون، به رشد محبوبیت این زبان می افزاید.
پایتون دارای کتابخانه تخصصی Matplotlib است که گزینههای گرافیکی و دیداری قدرتمندی را در اختیار کاربرمی گذارد . با این کتابخانه میتوانید نمودار، هیستوگرام، پراکندگی و دیگر نمودارهای معروف را با کمترین کدنویسی رسم کنید. با کتابخانه های زیرمجموعه این کتابخانه می توان نمودارهای جذاب و تعاملی را به آسانی طراحی کرد.
